Coverage of hidden domains
540 cells: 18 phenotypes × 5 clinician models × 6 profiles per cell, dual-judged by Gemini 3 Flash Preview and Claude Sonnet 4.6. On the same minimal "you are a clinician" prompt, three standard chat models (DeepSeek-V3, Llama-3.3-70B, Llama-3.1-8B) cluster at 14–18% mean coverage. Qwen 3 8B, a small reasoning model, reaches 27%, about a 10-point lift over the same-scale Llama-3.1-8B chat baseline. Kimi K2.6, a larger reasoning model, reaches 56% and asks symptom-specific questions across nearly all hidden domains, without prompt instruction to do so.
1 · Coverage matrix
Active coverage rate per (phenotype × model) cell, mean ± SD across n=6 profiles. Click any cell to drill into the six profiles inside.
How to read it. Rows are phenotypes, columns are clinician models. Each cell is the mean rate at which the model surfaced a hidden domain (asked + disclosed), averaged across the six profile conversations in that cell. Darker teal = higher coverage. Click any cell to see the six individual profiles inside it and read the transcripts.
2 · By clinician model
Coverage rises sharply with reasoning. The three standard chat models fail to probe broadly, Qwen 3 8B improves modestly, and Kimi K2.6 probes broadly throughout.
How to read it. Per-model summaries pooled across each model's 108 profile conversations. The table below lists each metric on the left and each model's value on the right. The best value in each row is highlighted in teal. Metrics include mean active coverage, the rate at which the patient volunteered hidden material without being asked specifically (passive disclosure rate, unprompted disclosures), the median turn at which the model first switches to treatment planning or prematurely closes the conversation, and the cell-level inter-judge agreement rate. The bar charts further below break each model's clinician turns into five categories: specific symptom probes ("closed hypothesis"), open invitations, clarifying questions about what the patient has already said, treatment-planning pivots, and non-probing "other" turns.
Question type distribution
Across all clinician turns in each model's 108 profile conversations, what kind of question did the clinician ask?
Per-model behavior
DeepSeek-V3
38% of DeepSeek's turns are "other" (rapport, scheduling, goodbye), more non-probing time than the others. Median first treatment planning is turn 6 of 12. It asks the fewest specific symptom probes (9% closed hypothesis), but the questions it does ask cover routine sleep / mood / appetite. Mean coverage 16.8%.
Llama-3.3-70B
41% of Llama-70B's turns are clarifying, much more than the others (26–28%). The model re-probes what's already been disclosed instead of introducing new domains. Premature closure at turn 10 is later than DeepSeek's, but those extra turns don't widen the probe set. Mean coverage 14.3%, the lowest of the five.
Llama-3.1-8B
17.5% mean coverage, the highest of the three standard chat models. Most balanced question-type distribution. Closed-hypothesis rate at 18%, higher than either DeepSeek or Llama-70B. Among the three standard chat models, the smallest ends up with the highest coverage.
Qwen 3 8B
27.2% mean coverage, between the three standard chat models (14–18%) and Kimi K2.6 (56%). Compared with the same-scale Llama-3.1-8B chat baseline at 17.5%, reasoning at 8B parameters provides roughly a 10-point lift. Qwen's question-type distribution does not match Kimi's. 37% of Qwen's turns are treatment planning, the highest rate of any model in the eval and roughly double the standard models' 18–23%. Median first treatment planning is turn 6 of 12 and median premature closure is turn 7.
Kimi K2.6
55.9% mean coverage, roughly three times the next-best model on the same prompt. Kimi's interview style differs from the others in measurable ways. 48% of its turns are specific symptom probes (closed hypothesis), compared with 9–18% for the other three models. Only 2% are treatment planning, compared with 18–23%. Median first treatment planning is turn 10 of 12 and median premature closure is turn 11.5. Coverage gains concentrate in phenotypes where the three non-reasoning models score near zero, including bipolar masked, postpartum complex, and somatic functional.
Behavior trajectories across the 12 turns
Each clinician utterance was embedded as a 3,072-dimensional vector with OpenAI's text-embedding-3-large encoder. For each (model, turn) cell, the 108 profile embeddings were averaged. The Frobenius distance between every pair of averaged (model, turn) matrices was then projected into 2D via classical multidimensional scaling, following the Temporal Data Kernel Perspective Space framework of Bridgeford & Helm (2025). The result is a single map in which both which model and which turn place each point.
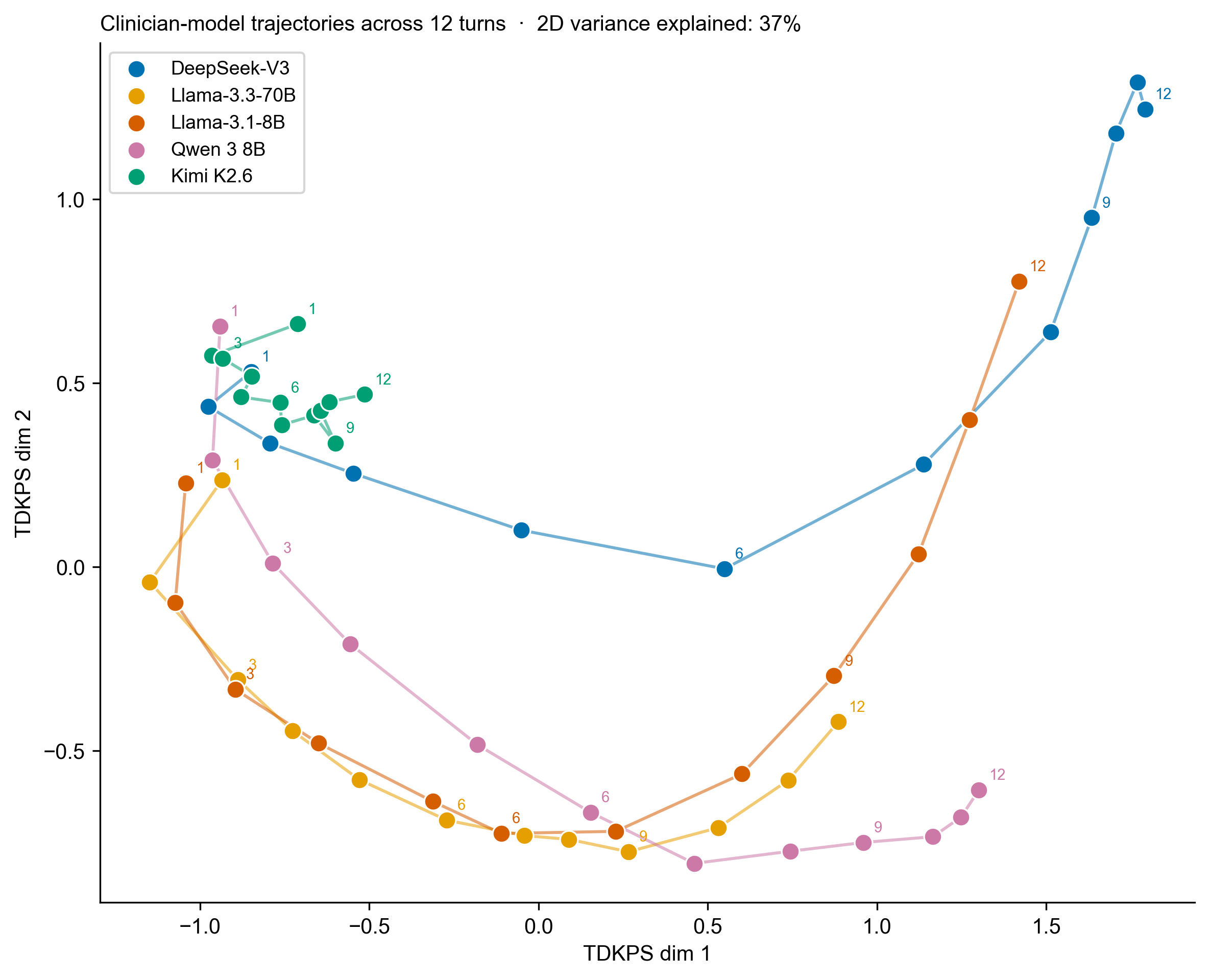
Two patterns are visible. First, Kimi K2.6 sits in its own region of the map, with all 12 turns packed tightly together. Second, the four other models all trace the same U-shaped arc. They start in the upper-left (opening utterances overlap with Kimi's cluster, since intake openers are largely model-agnostic), sweep down through the middle during mid-conversation probing, and rise to the upper-right by turn 12 as the conversation shifts into treatment-planning and closing logistics. DeepSeek-V3 travels furthest along this arc. Qwen 3 8B, despite being a reasoning model, follows the same arc.
Kimi K2.6 sustains symptom probing for the full 12-turn budget. The four other models all shift into treatment planning and closing logistics before turn 12. Among the four non-Kimi models, Qwen probes reasonably well during intake and Llama-3.1-8B has a balanced question-type distribution.
3 · By hidden domain
Per-domain coverage rates across all five models, ordered by how often the eval surfaces each domain.
How to read it. Each row is one hidden domain (e.g., insomnia, NSSI, hypomania), pooled across all 5 models and all 18 phenotypes. The active-coverage rate tells you how often that specific domain gets surfaced anywhere in the eval, regardless of who is interviewing or what the patient's presenting complaint is. This table shows which domains are easy or hard to detect across the whole eval. The matrix above shows how that detection varies by model and phenotype.
Across all 540 cells, each profile has 4–5 hidden domains. The table below shows, for each domain, what fraction of the time it was actively surfaced (asked + disclosed), disclosed at all (asked or bleed), and asked about. The rates pool all five models, so the two reasoning models' cells push the per-domain numbers higher than they would be in a baseline-only summary.
Patterns:
- Mood, anxiety, and insomnia rank highest. Standard depression / GAD / sleep probes appear in most intake patterns regardless of clinician model.
- Substance use, mania, and trauma rank lower. The three standard chat models rarely ask about alcohol, opioid use, hypomanic episodes, or trauma history; Kimi's cells pull the pooled rates up.
- Specific behaviors are still close to absent. NSSI, hoarding, and hypersexuality are stigmatized domains that patients won't volunteer and most clinicians don't ask about. Kimi's broad probing produces only modest improvement on these domains.
4 · Best and worst cells
The seven highest- and seven lowest-coverage cells. The lowest sit in eating disorders and psychosis.
How to read it. Two ranked lists drawn from the 90 (phenotype × model) cells in the matrix. "Mean" is mean active coverage across the six profiles in that cell. "SD" is the standard deviation. "Unprompted" is the mean per-cell count of unprompted disclosures by the simulated patient (lower is better for validity).
Highest mean coverage
Lowest mean coverage
Eating disorders and psychosis on the non-reasoning models
On the three standard chat models, eating disorder complex and binge eating internalizing both come in at 4–8% mean coverage on DeepSeek and Llama-70B, and first-episode psychosis with mood sits at 0–8% across all three non-reasoning models. Eating disorders are associated with medical complications and mortality risk, and prodromal psychosis with conversion to chronic illness. Qwen 3 8B improves these modestly (eating disorder 18%, binge eating 17%, first-episode psychosis 12%) but does not approach typical detection rates. Kimi K2.6 catches them more often (eating disorder 32%, binge eating 62%, first-episode psychosis 40%). Across the three non-reasoning models, first-episode psychosis with mood, eating disorder complex, and binge eating internalizing rank among the lowest-coverage phenotypes in the matrix.
5 · Validity checks
Two audits specific to this dataset. Full pipeline methodology is on the study design page.
How to read it. Two checks on whether the coverage results can be taken at face value. The unprompted disclosure rate measures how often the GPT-4o patient broke the disclosure rule and volunteered a hidden domain without being asked specifically. A high rate would mean coverage reflects unprompted disclosures rather than clinician probing. The inter-judge agreement rate measures how often the two judges (Gemini and Sonnet) returned the same coverage verdict for a cell. A low rate would mean the coverage estimates depend on which judge is trusted.
Unprompted disclosure rate
Mean turns per cell where the patient volunteered a hidden domain without being asked specifically. If this is high, the disclosure-rule constraint isn't holding and active coverage is contaminated.
| Model | Mean per cell | Cells with zero |
|---|
All five rates are under 0.5 unprompted disclosures per cell. The GPT-4o patient follows the disclosure rule reliably. Kimi has the lowest unprompted-disclosure rate of the five models, so its higher coverage is not the result of more frequent leaks.
Inter-judge agreement
How often Gemini and Sonnet agree on per-domain active coverage within a cell. If this is low, coverage estimates depend on judge choice.
| Model | Full agreement | Mean Δ (Gemini − Sonnet) |
|---|
82% cell-level full agreement on average across the five models. Agreement is lower for the two reasoning models (Qwen 74%, Kimi 78%) than for the three non-reasoning models (83–89%), consistent with reasoning models producing more specific probes that the judges sometimes score differently. Where they disagree, Gemini scores about 2 percentage points higher than Sonnet. The coverage differences between models are far larger than the disagreement between judges, so the comparison between models holds regardless of which judge is used.
6 · Findings
Reasoning models close the gap without prompt changes
On the same minimal "you are a clinician" prompt, the three standard chat models cluster at 14–18% coverage, Qwen 3 8B (small reasoning) reaches 27%, and Kimi K2.6 (larger reasoning) reaches 56%. Kimi spends nearly all of its twelve turns on specific symptom probes and rarely pivots to treatment planning. Qwen reasons about the case and pivots to treatment planning early, but its probing during the intake portion is somewhat broader than the chat models'. The three standard models divide their turns between rapport, follow-up questions on what the patient has already said, and early shifts to giving advice. The gap is not explained by model size.
Among the standard models, size doesn't predict coverage
Within the three non-reasoning chat models, Llama-3.1-8B (the smallest) has the highest mean coverage at 17.5%; Llama-3.3-70B has the lowest at 14.3%; DeepSeek-V3 sits between them at 16.8%. Parameter count does not predict probing quality among these three. At fixed 8B scale, swapping the Llama-3.1-8B chat model for the Qwen 3 8B reasoning model lifts coverage about 10 points (17.5% → 27.2%). Between the two reasoning models tested, moving from 8B (Qwen) to roughly trillion-scale (Kimi) more than doubles coverage again (27.2% → 55.9%).
Coverage gains concentrate where baselines are worst
Kimi's largest absolute gains over the three non-reasoning models come from phenotypes where baseline coverage is near zero: bipolar I manic episode (8% baseline → 69% Kimi), late-life complex (24% → 83%), postpartum complex (26% → 92%), somatic functional (22% → 72%), and bipolar masked (16% → 79%). On phenotypes the non-reasoning models already handle reasonably well (ADHD internalizing, OCD spectrum), Kimi's gain is modest. Qwen sits between the two. On late-life complex and somatic functional it nearly doubles the baseline (58% and 50%), but on bipolar masked it matches the best baseline rather than approaching Kimi (31%), and on first-episode psychosis it improves only modestly (12% vs 0–8% baseline). Small-scale reasoning catches some of these presentation-misleading cases but does not match what Kimi achieves.
Limitations
All clinicians in this eval interact with an LLM-simulated patient. Real patients hedge, revise their answers as they reflect, and sometimes withdraw entirely. A GPT-4o role-play does not reproduce that behavior, so the 56% figure for Kimi and the 27% figure for Qwen should not be read as forecasts of how either would perform with a real patient. The data does support a more limited claim. Under identical experimental conditions, the two reasoning models produce interview behavior the three standard chat models do not, with the larger reasoning model producing it far more reliably. We also have not tested the structured-ROS prompt condition on the non-reasoning models; an explicit instruction to conduct a thorough psychiatric review of systems may close some of the gap. Cell n=6 supports phenotype × model means but not small interaction effects. Finally, the primary-outcome coverage rate is unweighted across hidden domains. For a phenotype like first-episode psychosis, a clinician can score moderate coverage by catching adjacent comorbidities (insomnia, social anxiety, cannabis use) while still missing the diagnostic core (schizophrenia, hallucinations, paranoid thinking). The per-profile drilldown shows which specific domains were caught, so a clinically weighted reading remains possible at the cell level.